Sampling
You've probably already been introduced to the idea of sampling rate and the Nyquist theorem. We're not going to go into the math here, but just review the basic concepts.
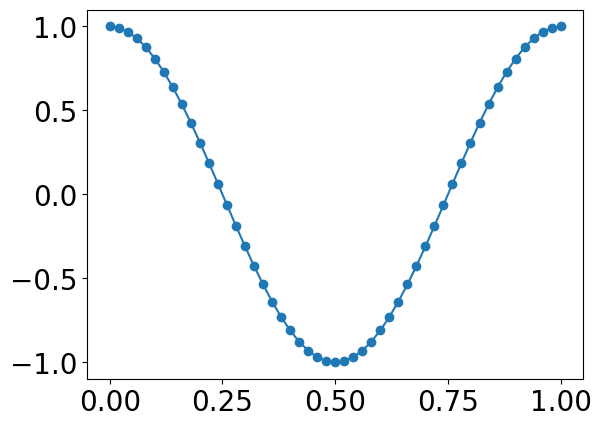
Remember that sound is continuous analog information. In order to store a wave of sound information on a computer, it needs to be converted to numbers that can represent this information.
Each number represents a discrete point along the analog signal. If we want to play back that representation, the computer has to "connect the dots" to recreate the sound wave.
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
t = np.linspace(0,1,51)
s = np.cos(2*np.pi * 1 * t)
plt.plot(t,s, marker = 'o')
The extent to which the digitized sound matches the original analog sound depends on the accuracy of the sampled representations. There are two variables that determine this acccuracy: bit depth and sample rate.
The standard sampling rate for most types of audio (e.g., CD quality) is 44,100. This means that there are 44,100 samples recorded every second.
Why do we use this rate?
It first relates to the range of human hearing.
(which is?)
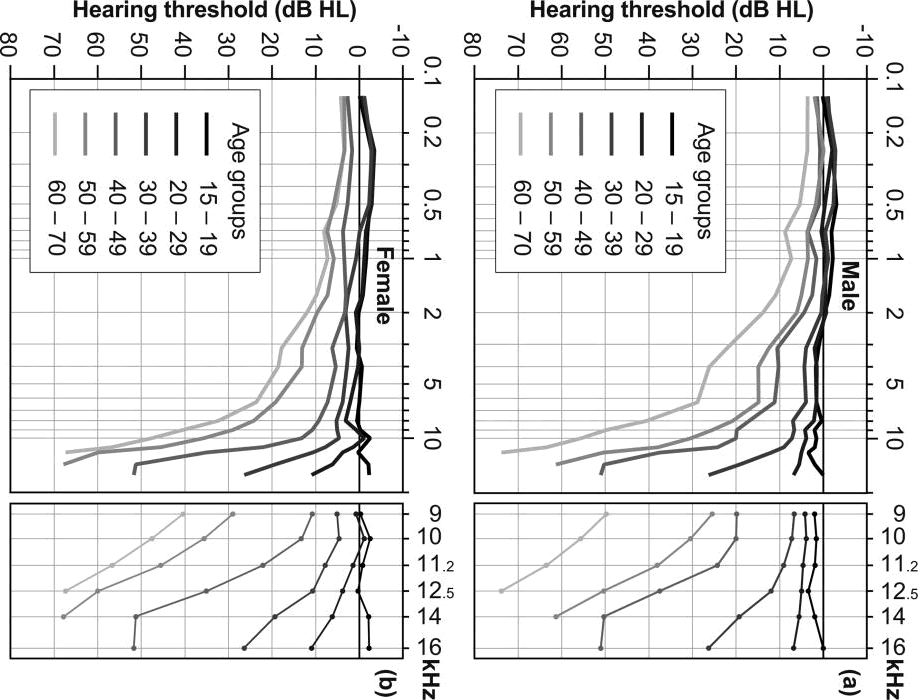
Humans with "perfect" hearing can hear sounds as low as 20Hz and as high as 20,000 Hz.
However, by the time most people are in their late 20s they are unlikely to have this range anymore. The high end is the first to go. Here's a depressing (or ear-care-motivating?) graph:
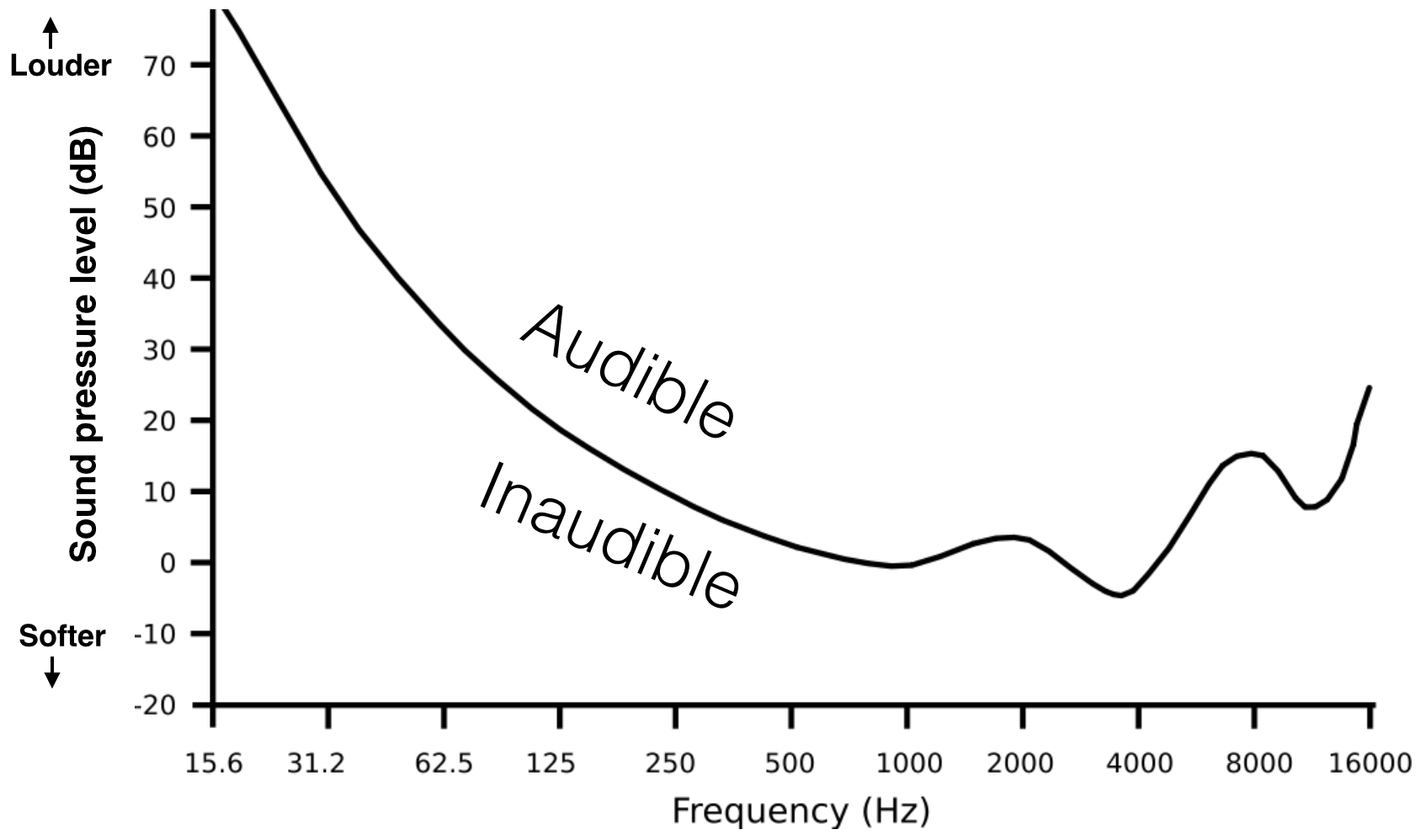
Refresher: not all frequencies are heard as equally loud. Some frequencies need a higher volume to be detectable by the ear, while others we are very sensitive to.
The following graph shows the quietest sounds (technically, the threshold sound intensity) a healthy 20-year-old can hear. For frequencies above 15000 Hz, threshold gets worse very rapidly.
Aside #1: Notice the dips in sensitivity between 2 and 5KHz? Any idea why this range is important?
Back to sampling rate! In order to capture a sound signal (as faithfully as possible), what is the slowest sampling rate we can use?
To be able to accurately capture a frequency we need to have a sample rate that's at least twice the fastest frequency otherwise we get aliasing (more on this later). This is minimum sample rate is referred to as the Nyquist frequency.
We don't want to cut off frequencies that are in the normal range of human hearing, the default sampling rate is a bit more than double of the conservative upper-limit of human hearing.
Aside #2: Anyone know why we don't just sample at 40,000?
One reason has to do with compatibility with video recording. 44,100 samples/s can fit digital audio samples into an analog video channel running 25 or 30 FPS.
However, for that we'd only need 40,050 samples/s.
It has to do with leaving space for something called a transition band or a skirt when attenuating frequencies over the 20k limit, we want to avoid a sharp "cutoff" and instead offer a smooth gradual decrease. (More on this later).
Of course, there are other sampling rates possible. For instance, 48kHz is the standard for DVD quality. Some people choose to record at 96kHz (e.g., standard for HD DVD and Blue Ray).
Alasing
Recap: the sample rate needs to be frequent enough to capture the amplitude changes of extremely fast moving frequencies. So we set our sampling rate to be roughly double the frequency of the maximum frequency we are capable of hearing.
Say we're using a sampling rate of 44,100. What frequencies might we record that would be problematic according to the Nyquist theorem?
Any frequency content above the Nyquist frequency (defined as half the sample rate), will create artifacts. Let's look at an example:
#Values for axis 1: fs=51,
#s1 = 10Hz,
#s2 = 45Hz
t = np.linspace(0,1,51)
s1 = np.cos(2*np.pi * 10 * t)
s2 = np.cos(2*np.pi * 45 * t)
#Plot top graph
fig, (ax1, ax2) = plt.subplots(2, 1, sharex=True)
ax1.plot(t, s1)
ax1.plot(t, s2, marker="o")
#Values for axis 2: fs=500,
#s3 = 10Hz,
#s4 = 45Hz
t2 = np.linspace(0,1,500)
s3 = np.cos(2*np.pi * 10 * t2 )
s4 = np.cos(2*np.pi * 45 * t2 )
#Plot bottom graph
ax2.plot(t2, s3, t2, s4)
ax2.plot(t, s2, marker="o", c='orange')
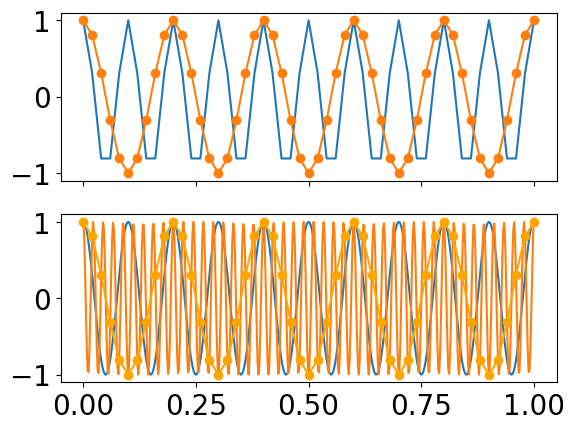
What does this plot demonstrate?
Can we predict where artefacts will be (in terms of frequency content) due to aliasing??
Hint: look at relation between the sample rate, desired frequency, and resulting frequency
Yes. They will appear at the absolute value of the frequency - sample rate (times nearest integer of f/fs if > 1)
nint = nearest integer
formula for finding alias frequency:
$ F(a) = | f - fs * nint(\frac{f}{fs}) | $
Let's imagine we were sampling a signal (at 44,100) that included the following frequencies (all in KHz): 22.0, 24.0, 33.0, and 40.0. We simply subtract the the "problem" or artefact frequency from sample rate:
22.0 = # Is this a problem?
22.1 = #Is this a problem?
24.0 = # What about this?
33.0 = # Or this?
40.0 = # Or this?
So in the last two cases, we end up with perceptual artifacts in the recorded sound. This phenomenon is called aliasing (or "fake" frequencies.) So, how do we avoid this problem?
The way we deal with this is to apply a low-pass filter (which allow frequencies below some threshold--typically the Nyquist--to pass through) to remove any of these extreme high frequencies before sampling to ensure we don't get artifacts.
This is called "anti-aliasing."This is applied before the sound gets sampled through an analog to digital converter.
Since we are not using a DAW and are creating sounds "from scratch" it will be important you understand this concept.
Note that we can also get aliasing of different frequencies by sampling at lower sampling rates. It all depends on the relation between the frequencies sampled and the sampling rate.
In either case, if a sine wave is changing quickly, and the sampling rate isn't fast enough to capture it, this can result in a set of samples that look identical to a sine wave of lower frequency!
As we saw above, the effect of this is that the higher-frequency contributions now act as impostors (i.e., aliases) of lower-frequency information.
IF one recorded high frequency content intentionally, how could we play it back so that we could hear it?
(By slowing down the sampling rate). You will play around with altering the "playback" sampling rate of recodings during our class activity.
If we have a recording sampled at 44,100 but we tell a program that the original sample rate was really 22,050 what will be the effect?
If we have a recording sampled at 22,050 but we tell a player to play back at a sample rate of 44,100 what will be the effect?
These are radio emissions from Saturn. The radio waves are closely related to the auroras near the poles of the planet.
This recording has been modified so that 73 seconds corresponds to 27 minutes. Since the frequencies of these emissions are well above human hearing range, they are shifted downward by a factor of 44.